
TCP Retransmissions: Der stille Performance-Killer – Ursachensuche und Behebung mit Wireshark
„Das Netzwerk ist langsam.“ Wenn dieser Satz in der IT-Abteilung fällt, bricht bei vielen Administratoren erst einmal leichter Stress aus. Die Monitoring-Tools zeigen grünes Licht: Die CPU-Last der Server ist im Keller, der RAM ist ausreichend dimensioniert und die Bandbreite der Uplinks ist bei weitem nicht ausgeschöpft. Und doch beschweren sich die Anwender über zähe Datenbankabfragen, abbrechende Dateiübertragungen oder ruckelnde Video-Calls.
In meiner jahrelangen Praxis als Netzwerkanalyst habe ich gelernt: Wenn die Metriken auf der Oberfläche gut aussehen, das Nutzererlebnis aber katastrophal ist, lohnt sich fast immer ein tiefer Blick in den TCP-Stack. Meistens stoßen wir dort auf ein Phänomen, das wie kaum ein anderes die Effizienz digitaler Prozesse untergräbt: TCP Retransmissions.
In diesem Artikel tauchen wir tief in die Materie ein. Ich zeige dir, warum Retransmissions entstehen, wie sie die Performance deiner Anwendungen sabotieren und wie du ihnen mit Wireshark auf die Schliche kommst.
Das typische Szenario: Wenn “genug Bandbreite” nicht mehr hilft
Stell dir ein mittelständisches Unternehmen vor. Die Zentrale ist über eine dedizierte 1-Gbit/s-Leitung mit dem Rechenzentrum verbunden. Eigentlich genug Kapazität für alle Workloads. Doch seit der Einführung eines neuen ERP-Systems klagen die Außenstellen über massive Latenzen.
Der Standardreflex vieler IT-Abteilungen: “Wir brauchen mehr Bandbreite.” Doch oft ist das ein teurer Trugschluss. In einem Projekt, das ich vor Kurzem betreut habe, lag die Auslastung der Leitung bei gerade einmal 20 %. Trotzdem fühlte sich die Anwendung an wie zu ISDN-Zeiten.
Die Ursache war nicht mangelnder Durchsatz, sondern eine instabile Strecke, die zu Packetverlusten führte. Und genau hier greift der Korrekturmechanismus von TCP ein: die Retransmission. Das Problem dabei ist, dass TCP ein sehr “höfliches”, aber auch vorsichtiges Protokoll ist. Sobald es merkt, dass Daten verloren gehen, drosselt es die Übertragungsrate massiv, um das Netz nicht weiter zu überlasten. Wir haben es hier mit einem klassischen Bottleneck zu tun, das nicht durch die Leitungskapazität, sondern durch die Fehlerkorrektur des Protokolls entsteht.
Technischer Hintergrund: Warum gibt es TCP Retransmissions?
Um zu verstehen, wie wir das Problem lösen, müssen wir kurz die Mechanik von TCP (Transmission Control Protocol) betrachten. TCP ist ein verbindungsorientiertes Protokoll, das sicherstellt, dass Datenpakete vollständig und in der richtigen Reihenfolge ankommen.
Das Prinzip der Bestätigung (ACK)
Jedes gesendete Datenpaket muss vom Empfänger bestätigt werden (Acknowledgement, kurz: ACK). Erhält der Sender innerhalb einer gewissen Zeit (dem Retransmission Timeout, RTO) keine Bestätigung, geht er davon aus, dass das Paket im “Nirvana” des Netzwerks verschwunden ist.
Die Kettenreaktion
Wenn ein Paket verloren geht, passiert Folgendes:
- Warten: Der Sender wartet auf das ACK.
- Timeout: Die Zeit läuft ab.
- Erneutes Senden: Das Paket wird noch einmal verschickt (Retransmission).
- Congestion Control: TCP vermutet eine Überlastung im Netz und verkleinert das sogenannte “Congestion Window”. Das bedeutet, es werden weniger Daten gleichzeitig gesendet, bevor auf eine Bestätigung gewartet wird.
- Das Ergebnis: Selbst bei minimalen Packetverlusten (schon 1 % kann ausreichen) bricht der effektive Durchsatz dramatisch ein. Die Latenz steigt gefühlt exponentiell an.
Analyse mit Wireshark: Den Fehlern auf der Spur
Wireshark ist für uns Netzwerkanalysten das Skalpell. Ohne einen Paketmitschnitt (Trace) raten wir nur – mit Wireshark wissen wir genau, was auf dem Draht passiert.
1. Den Trace richtig aufnehmen
Bevor wir analysieren, müssen wir die Daten sauber erfassen. Ein Trace direkt auf dem Client oder Server ist oft der erste Schritt. Wenn du jedoch Infrastrukturkomponenten wie Firewalls oder Switches im Verdacht hast, ist ein Mirror-Port (SPAN) oder ein Netzwerk-TAP am entsprechenden Hop unumgänglich.
2. Der entscheidende Filter
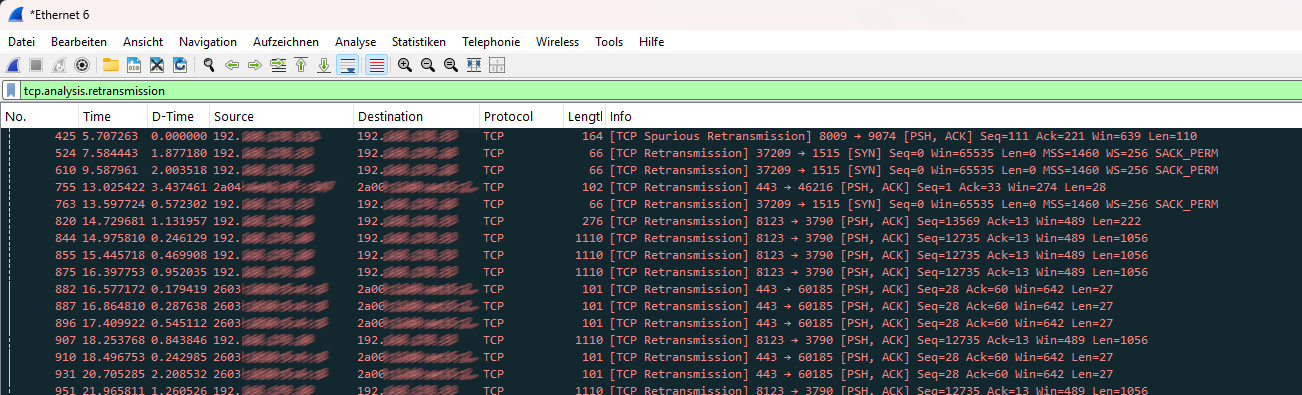
Öffne Wireshark und lade deinen Trace. Die Flut an Paketen kann erschlagend wirken. Nutze daher den eingebauten Experten-Filter für TCP-Retransmission Probleme:
Gib diesen Ausdruck in die Filterzeile ein. Wenn die Liste nun viele Zeilen in Schwarz mit roter Schrift (Standard-Farbschema) anzeigt, hast du den Beweis: Dein Netzwerk leidet unter Retransmissions.
3. Die Experten-Analyse nutzen
Gehe auf Analyze -> Expert Information. Wireshark kategorisiert hier Probleme in “Notes”, “Warnungen” und “Fehler”.
Profi Tipp: Statt über das Menü zu gehen, kannst du auch unten links im Fenster auf den Kreis klicken.
Achte in der Expert Info besonders auf:
Fast Retransmissions: Hier hat der Empfänger durch “Duplicate ACKs” signalisiert, dass ein Paket fehlt. Das ist “besser” als ein Timeout, da der Sender nicht so lange warten muss.
Out-of-Order: Pakete kommen in der falschen Reihenfolge an. Oft ein Zeichen für Load-Balancing-Probleme auf Hardware-Ebene.
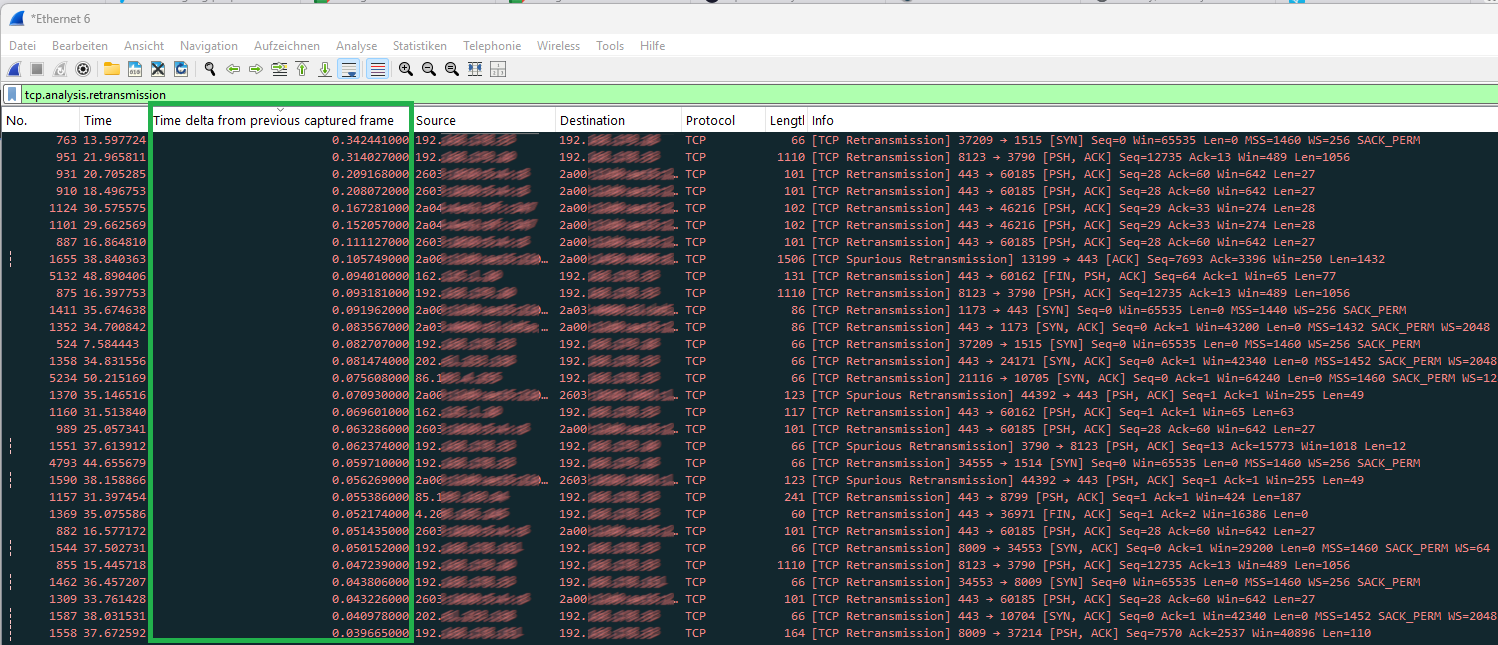
4. Zeitabstände analysieren
Schau dir in der Paketliste die Spalte “Delta Time” an (falls nicht vorhanden: Rechtsklick auf die Spaltenüberschrift -> Column Preferences -> Type: Delta Time). Wenn zwischen dem Original-Paket und der Retransmission mehrere hundert Millisekunden liegen, spüren das die Anwender unmittelbar. Um einen schnellen Überblick zu erhalten, hilft es hier nach der Delta Time zu sortieren. So kann man schnell herausfinden, ob es hier größere Gaps gibt.
Des Weiteren kann auch die Summe der einzelnen Retransmission und deren Zeit von Bedeutung sein.
Häufige Ursachen: Woher kommen die Packetverluste?
In meiner Praxis kristallisiert sich immer wieder eine Handvoll üblicher Verdächtiger heraus:
A. Defekte Hardware (Layer 1)
Es klingt banal, aber ein geknicktes Glasfaserkabel, ein defektes SFP-Modul oder ein schlecht gecrimptes Cat6-Kabel sind für einen Großteil der Fehler verantwortlich. Diese führen zu CRC-Fehlern auf den Switch-Ports, was wiederum Pakete verwirft.
Check: Prüfe die Interface-Counter deiner Switches (show interfaces bei Cisco/HP). Suche nach “Input Errors” oder “CRC Errors”.
B. Überlastverhalten und Bufferbloat
Wenn ein Switch oder Router mehr Daten empfängt, als er weiterleiten kann, füllt er seine Puffer. Sind diese voll (Tail Drop), werden neue Pakete einfach verworfen. Besonders kritisch ist dies an Übergängen von hoher auf niedrige Bandbreite (z.B. von 10 Gbit/s Core auf 1 Gbit/s Access).
C. MTU-Mismatches und Fragmentierung
Wenn ein Paket zu groß für einen Teilabschnitt des Weges ist (z.B. durch VPN-Header), muss es fragmentiert werden oder es wird verworfen. ICMP-Messages (“Destination Unreachable, Fragmentation Needed”), die normalerweise helfen würden, werden oft von übervorsichtigen Firewalls geblockt. Das Ergebnis sind “Black Hole”-Router und – du rätst es – TCP Retransmissions.
D. Security Appliances
Firewalls, IPS-Systeme und Deep Packet Inspection (DPI) können zum Nadelöhr werden. Wenn die CPU der Firewall bei Lastspitzen auf 100 % geht, ist das Erste, was sie tut: Pakete wegschmeißen.
Lösung & Best Practices: So bekommst du das Netz wieder schnell
Wenn wir die Ursache identifiziert haben, geht es an die Behebung. Hier sind die bewährtesten Strategien:
Physische Schicht bereinigen: Tausche verdächtige Kabel und SFPs proaktiv aus. Ein “geht ja meistens” reicht in modernen Hochgeschwindigkeitsnetzen nicht mehr aus.
TCP Window Scaling optimieren: Stelle sicher, dass moderne Betriebssysteme ihre “Receive Window” (RWIN) dynamisch anpassen können. Das hilft, die Bandbreite trotz Latenz besser auszunutzen.
Flow Control und QoS: Nutze Quality of Service (QoS) nur dort, wo es wirklich nötig ist (Voice over IP). In reinen Datennetzen kann ein falsch konfiguriertes QoS das Überlastverhalten sogar verschlimmern.
MSS Clamping: Bei VPN-Verbindungen ist “MSS Clamping” oft der Retter. Dabei wird die Maximum Segment Size im TCP-Handshake künstlich verringert, damit inklusive aller VPN-Header die MTU der Strecke nicht überschritten wird.
Puffer-Management: Prüfe, ob deine Switche “Deep Buffers” unterstützen, falls du viele Bursty-Workloads (wie Backups oder Storage-Traffic) hast.
Fazit + Handlungsempfehlung
TCP Retransmissions sind mehr als nur ein technisches Detail – sie sind ein hocheffizientes Warnsignal für den Zustand deiner Infrastruktur. Eine saubere Netzwerkanalyse mit Wireshark erlaubt es uns, weg vom “Raten und Tauschen” hin zu einer evidenzbasierten Fehlerbehebung zu kommen.
Meine Empfehlung für dein weiteres Vorgehen:
Führe bei Performance-Beschwerden immer eine Basismessung (Baseline) durch. Wie viele Retransmissions sind “normal” in deinem Netz? (In der Regel sollten sie unter 0,1 % liegen).
Schule deine Administratoren im Umgang mit Wireshark. Es ist das wichtigste Werkzeug im Werkzeugkasten.
Wenn du an einen Punkt kommst, an dem du die Pakete siehst, aber die Ursache im komplexen Zusammenspiel der Protokolle nicht findest: Hol dir externe Expertise. Oft spart eine zweistündige Analyse durch einen Profi Tage an frustrierender Fehlersuche.
Ein gesundes Netzwerk ist die Basis für jedes digitale Business. Lass nicht zu, dass TCP Retransmissions zu deinem unsichtbaren Bottleneck werden.
💡 Praxis-Tipp:
Erfahre in diesem Artikel, wie sich Retransmissions im Gesamtbild äußern und wie du
Performance-Engpässe im Gigabit-Netzwerk präzise lokalisierst
Das passende Handwerkszeug für die Suche findest du in meinen
Wireshark Guides für IT-Administratoren
FAQ – Häufig gestellte Fragen
1. Wie viel Prozent TCP Retransmissions sind normal?
In einem lokalen Netzwerk (LAN) sollten die Retransmissions gegen Null tendieren (unter 0,01 %). In WAN-Strecken oder über Internet-Verbindungen sind Werte bis zu 1 % oft unvermeidbar und werden vom Protokoll gut kompensiert. Steigt der Wert über 2-3 %, wird die Performance-Einbuße für den Endanwender deutlich spürbar.
2. Was ist der Unterschied zwischen einer Retransmission und einer Spurious Retransmission?
Eine echte Retransmission tritt auf, wenn ein Paket tatsächlich verloren ging. Eine “Spurious Retransmission” (fälschliche Retransmission) passiert, wenn der Sender ein Paket erneut schickt, obwohl das Original noch unterwegs ist (z.B. durch extreme Latenzschwankungen/Jitter). Wireshark kann diese unterscheiden und markiert sie entsprechend.
3. Kann WLAN die Ursache für Retransmissions sein?
Ja, absolut. WLAN ist ein “Shared Medium” und sehr anfällig für Interferenzen. Auf Layer 2 (WLAN) gibt es eigene Korrekturmechanismen, aber wenn diese scheitern, schlägt der Fehler bis auf Layer 4 (TCP) durch und erzeugt dort Retransmissions.
4. Hilft mehr Bandbreite gegen Retransmissions?
Meistens nicht. Wenn die Retransmissions durch Paketverluste aufgrund von Hardwarefehlern oder MTU-Problemen entstehen, wird eine größere Leitung das Problem nicht lösen. Nur wenn die Ursache echtes “Congestion” (Überlastung) durch eine zu kleine Leitung ist, hilft ein Upgrade.
5. Warum zeigt Wireshark so viele Retransmissions bei einer eigentlich schnellen Verbindung?
Das liegt oft am TCP-Überlastungsalgorithmus. Wenn TCP merkt, dass die Gegenseite sehr schnell empfangen kann, “testet” es das Limit aus, bis das erste Paket verworfen wird. Ein gewisses Maß an Retransmissions bei massiven Datenübertragungen ist also systemimmanent, sollte aber das Gesamtbild nicht dominieren.