

Wireshark für Admins: Die 10 wichtigsten Display-Filter für den IT-Alltag
„Das Netzwerk ist langsam.” Wenn du im IT-Support oder in der Administration arbeitest, ist dieser Satz vermutlich dein persönlicher Endgegner. Es ist die vage Beschreibung eines Problems, das alles sein kann: ein sterbender Switch-Port, ein überlasteter SQL-Server, ein falsch konfigurierter Virenscanner oder schlichtweg ein defektes Patchkabel. Und meistens beginnt damit das übliche Spiel: Das Netzwerkteam sagt „bei uns ist alles grün”, das Applikationsteam sagt „an uns liegt’s nicht” – und der Anwender wartet weiter. Dieses Fingerpointing kostet Unternehmen mehr Zeit und Geld als das eigentliche Problem.
Monitoring-Tools wie Checkmk oder Zabbix sagen dir, dass etwas nicht stimmt – Wireshark sagt dir, warum. Und vor allem: Es liefert Beweise, die die Schuldfrage objektiv klären, statt sie im Kreis zu drehen.
Wer Wireshark zum ersten Mal öffnet, fühlt sich oft wie ein Pilot ohne Training in einem vollbesetzten Cockpit. Tausende von Paketen rauschen pro Sekunde vorbei. Ohne die richtigen Filter suchst du nicht nach der Nadel im Heuhaufen – du suchst nach einer ganz bestimmten Nadel in einem Heuhaufen, der gerade von einem Wirbelsturm durchgeschüttelt wird.
In diesem Artikel zeige ich dir – basierend auf meiner täglichen Arbeit als freiberuflicher Netzwerkanalytiker – welche 10 Display-Filter du brauchst, um Performance-Probleme in Unternehmensnetzen innerhalb von Minuten einzugrenzen.
Das typische Phantom-Problem: Wenn alle Werte grün sind, aber nichts funktioniert
Stell dir vor, ein Anwender meldet, dass die ERP-Software sporadisch „hängt”. Ping zum Server: stabile 1 ms. CPU-Last: 5 %. Uplink-Auslastung: 10 %. Standard-Tools zeigen keine Fehler.
In meiner Beratungspraxis erlebe ich genau dieses Szenario regelmäßig. Viele Admins tauschen an diesem Punkt auf Verdacht Hardware oder erhöhen VM-Ressourcen – teures Raten ohne Datenbasis. Mit einer gezielten Netzwerkanalyse per Wireshark sehen wir stattdessen sofort: Die Anwendung wartet auf eine Antwort, die nie ankommt. Oder TCP Retransmissions bremsen den Datenfluss massiv aus. Das Problem liegt im Protokoll-Verhalten, nicht in der Bandbreite.
Capture Filter vs. Display Filter: Ein Unterschied, der entscheidet
Bevor wir zu den Filtern kommen, kurz das Wichtigste vorab. Wireshark kennt zwei Filtertypen:
- Capture Filter: Bestimmen, was überhaupt aufgezeichnet wird (z. B.
host 192.168.1.10). - Display Filter: Bestimmen, was du aus der aufgezeichneten Datenmenge siehst (z. B.
tcp.analysis.retransmission). Dein schärfstes Werkzeug.
Wann du lieber alles aufzeichnest: In vielen Fällen ist es die bessere Entscheidung, den Capture Filter ganz wegzulassen und den gesamten Traffic zu erfassen. Besonders bei Problemen, die durch Cross-Traffic ausgelöst werden – also wenn eine andere Applikation oder ein anderer Netzwerkteilnehmer die eigentliche Störung verursacht – siehst du das Zusammenspiel nur im vollständigen Mitschnitt. Auch bei Authentifizierungsproblemen ist das entscheidend: Hast du deinen Capture Filter nur auf die betroffene Applikation gesetzt, fehlt dir im Nachhinein der Kontext. Du siehst zum Beispiel, dass eine Verbindung abbricht, aber nicht, dass kurz davor eine LDAP- oder Kerberos-Anfrage ins Leere lief – ein typisches Muster, das ich in meinem Beitrag zu Verbindungsabbrüchen ausführlich beschreibe. Diese Zusammenhänge nachträglich zu rekonstruieren ist schwierig bis unmöglich – und genau das macht die Analyse unnötig zeitaufwändig.
Wann ein Capture Filter sinnvoll ist: In stabilen, hochausgelasteten Umgebungen, in denen du das Problem bereits gut eingegrenzt hast, kann ein Capture Filter die Datenmenge erheblich reduzieren. Eine PCAP-Datei, die unkontrolliert wächst, wird schnell unhandlich – und ein Wireshark, das beim Öffnen einer 10-GB-Datei abstürzt, hilft niemandem. Wenn du weißt, dass du nur den Verkehr zwischen einem Client und einem bestimmten Server brauchst, spart host 10.1.1.5 viel Speicherplatz und hält die Analyse übersichtlich. Gerade wenn du gezielt auf Paketverluste oder ein TCP Window-Problem zwischen zwei bekannten Hosts eingrenzt, ist ein enger Capture Filter das richtige Mittel.
Die Faustregel: Im Zweifel alles aufzeichnen und per Display Filter analysieren. Zu viele Daten lassen sich eingrenzen – zu wenige Daten lassen sich nicht rekonstruieren.
Display-Filter verändern die Daten nicht – sie machen sie sichtbar. Für ihren effektiven Einsatz brauchst du ein solides Verständnis von TCP/IP: Wie sieht ein Three-Way-Handshake aus? Wie funktioniert Window Scaling? Warum ist ein TCP-Reset oft der digitale Hilfeschrei einer überlasteten Anwendung?
Die 10 wichtigsten Wireshark Display-Filter für die Praxis
1. TCP Retransmissions aufspüren
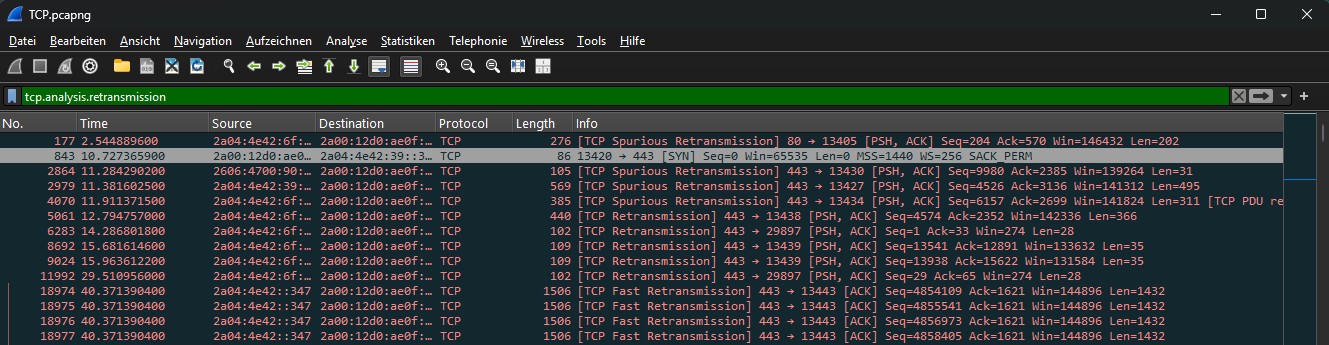
Der wichtigste Filter für die Diagnose von Paketverlusten. Wenn ein Paket im Netz verloren geht, bemerkt TCP dies und sendet es erneut – mit messbaren Wartezeiten als Konsequenz.
Warum das wichtig ist: Schon eine Verlustrate von 1–2 % kann eine gefühlte Verlangsamung um den Faktor 10 bedeuten. Retransmissions sind oft das erste sichtbare Symptom eines tieferliegenden Problems – und häufig begleitet von Duplicate ACKs und Out-of-Order-Paketen, die zusammen ein klares Bild ergeben. Was genau hinter diesen drei Symptomen steckt und wie du sie voneinander unterscheidest, erkläre ich ausführlich in meinem Beitrag TCP Retransmissions, Duplicate ACKs und Out-of-Order – was die Unterschiede wirklich bedeuten.
Praxis-Tipp: Treten Retransmissions nur bei einem bestimmten Ziel auf? Dann liegt das Problem wahrscheinlich auf dem Weg dorthin – Router, Firewall, WAN-Strecke. Treten sie überall auf? Prüfe die lokale NIC oder den Switch-Stack. Wie du Paketverluste methodisch misst und lokalisierst, zeige ich dir in meinem Guide Packet Loss messen und analysieren mit Wireshark.
Warum Paketverluste die Performance so massiv drosseln, erkläre ich im Detail: TCP Retransmissions – Ursachen finden und Netzwerkspeed zurückgewinnen.
2. IP-Adressen filtern: Den Verdächtigen isolieren
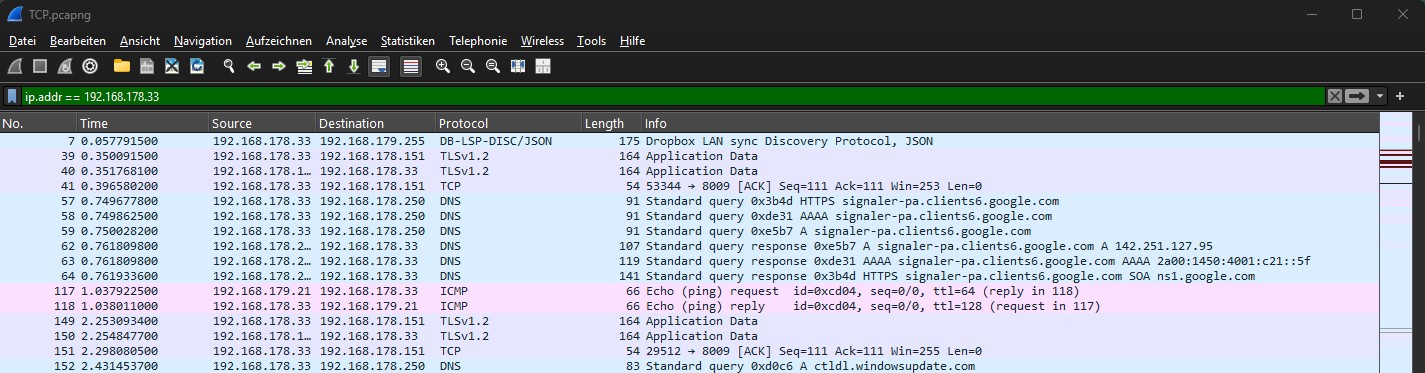
Simpel, aber hocheffektiv. Zeigt dir den gesamten Datenverkehr – ein- und ausgehend – für ein spezifisches Gerät.
Erweiterung: Nutze ip.src == ... für Quelladressen oder ip.dst == ... für Zieladressen. Für die Analyse zwischen zwei Hosts: ip.addr == 10.0.0.1 && ip.addr == 10.0.0.2
Achtung, Stolperfalle: Zum Ausschließen einer Adresse niemals !ip.addr == 192.168.1.10 schreiben – das liefert nicht das erwartete Ergebnis, weil der Ausdruck auf Quell- und Zieladresse gleichzeitig wirkt. Richtig ist: !(ip.addr == 192.168.1.10). Einer der häufigsten Anfängerfehler in Wireshark überhaupt.
3. TCP Resets: Verbindungsabbrüchen auf den Grund gehen
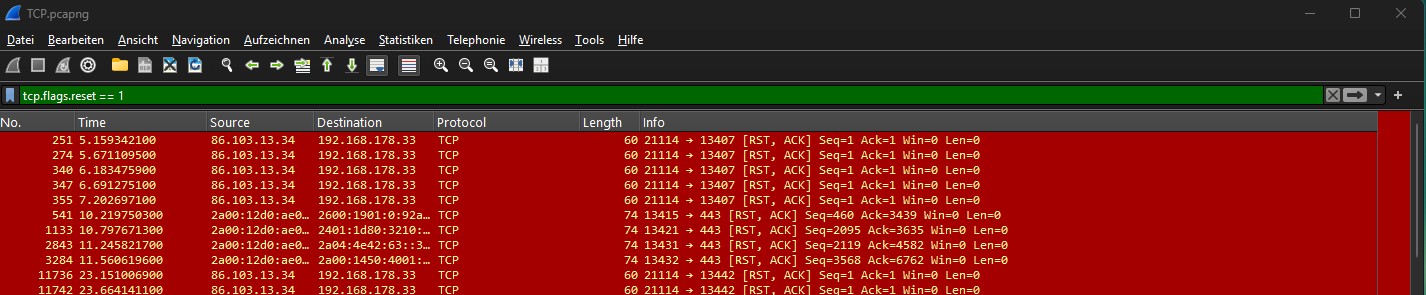
Ein TCP Reset (RST) ist das sofortige, harte Beenden einer Verbindung – ohne Vorwarnung.
Häufige Ursachen: Eine Firewall blockt die Verbindung, ein Dienst ist auf dem Zielserver nicht gestartet, oder eine Anwendung stürzt ab.
Aus der Praxis: Ein Kunde klagte über Verbindungsabbrüche zum SQL-Server. Der Filter zeigte massenhaft RST-Pakete von der Firewall-IP. Ursache: Ein IPS-Modul stufte legitime SQL-Abfragen fälschlicherweise als SQL-Injection ein. Ergebnis: Ursache nach wenigen Stunden Analyse belegt – statt tagelanger Diskussionen zwischen Datenbank- und Netzwerkteam. Wie du solche Verbindungsabbrüche systematisch analysierst – von RST-Paketen über Timeouts bis zu Firewall-bedingten Abbrüchen – beschreibe ich in einem eigenen Beitrag.
4. Antwortzeiten messen: Netzwerk oder Anwendung?
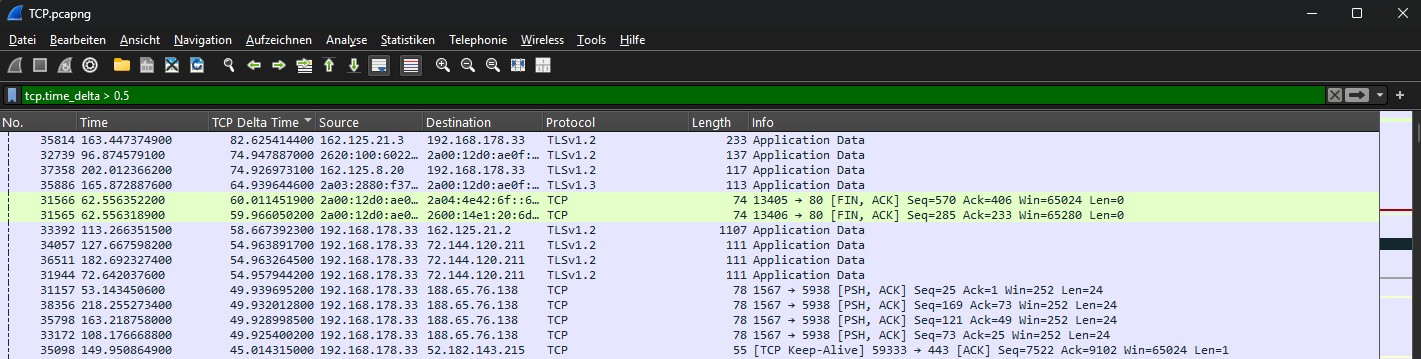
Zeigt alle Pakete, bei denen seit dem letzten Paket im TCP-Stream mehr als 500 ms vergangen sind.
Einsatzbereich: Ideal, um die Schuldfrage zu klären. Wenn der Client eine Anfrage schickt und der Server erst nach 800 ms antwortet, hast du den Beweis: Das Netzwerk ist schnell, aber die Anwendung oder Datenbank auf dem Server ist der Bottleneck. Diese Erkenntnis erspart endlose Diskussionen zwischen Netzwerk- und Applikationsteams. Wie mächtig dieser eine Filter in der Praxis ist, zeigt mein Praxisfall zu sequentiellen Datenbank-Requests und dem N+1-Query-Muster: Dort war nicht das Netzwerk schuld, sondern eine Anwendung, die tausende Einzelabfragen nacheinander abschickte. Den methodischen Rahmen für eine solche Analyse findest du in meinem Überblick zur Wireshark-Netzwerkanalyse für Performance-Fehler.
5. DNS-Fehler aufdecken

Hinter vielen vermeintlichen Netzwerkfehlern steckt ein DNS-Problem. Dieser Filter zeigt alle DNS-Antworten ohne „Success”-Status – z. B. „Name Error” oder „Refused”.
Szenario: Ein Server braucht 5 Sekunden zum Starten einer Applikation? Oft versucht er, einen Hostnamen aufzulösen, der nicht mehr existiert – und wartet auf den DNS-Timeout. Klassisch, leicht übersehen. Genau deshalb ist es wichtig, beim Mitschneiden nie zu früh zu filtern: Hättest du nur den Traffic der betroffenen Applikation aufgezeichnet, wäre die DNS-Anfrage – die auf einem anderen Port läuft – möglicherweise gar nicht im Capture gelandet.
6. HTTP-Fehlercodes filtern
http.response.code >= 400
Wenn Webdienste oder APIs Probleme machen, zeigt dir dieser Filter sofort alle Client-Fehler (4xx) und Server-Fehler (5xx).
Nutzen: Du siehst sofort, ob ein Webserver 404 Not Found oder 500 Internal Server Error zurückgibt – ohne mühsam Logfiles zu wälzen. Und anders als im Server-Log siehst du hier auch, welcher Client betroffen war und wie lange die Antwort gedauert hat.
7. Duplicate ACKs: Der Vorbote von Paketverlusten

Wenn der Empfänger ein Paket erhält, aber eine Lücke in der Sequenznummer bemerkt, schickt er Duplicate ACKs: „Mir fehlt da was!”
Bedeutung: Duplicate ACKs sind oft der direkte Vorbote von Retransmissions und ein klares Zeichen für Überlastverhalten in Switches oder Routern. Drei aufeinanderfolgende Duplicate ACKs lösen den TCP Fast Retransmit aus – der Sender schickt das fehlende Paket sofort erneut, ohne auf den Timeout zu warten. Den genauen Zusammenhang zwischen Duplicate ACKs, Out-of-Order-Paketen und Retransmissions – und was du in der Praxis daraus ableitest – erkläre ich ausführlich in diesem Beitrag.
8. TCP Window Size: Wenn der Empfänger aufgibt

Das TCP Window gibt an, wie viele Daten ein Empfänger puffern kann. Sinkt es gegen null (Zero Window), sagt der Empfänger: „Stopp – ich kann nicht mehr.”
Noch präziser: Mit tcp.analysis.zero_window filterst du direkt auf die Pakete, in denen Wireshark ein Zero Window erkannt hat – ohne selbst einen Schwellwert wählen zu müssen.
Analyse: Ein klassischer Hinweis auf CPU-seitige Überlastung des Empfängers. Der Rechner schaufelt die Daten nicht schnell genug aus dem IP-Stack in die Anwendung. Oft in Verbindung mit trägen Terminalserver-Sitzungen oder Datenbank-Clients zu sehen. Das gesamte Konzept hinter Window Size und Window Scaling – inklusive der Frage, warum falsche Scaling-Faktoren die Performance heimlich drosseln – erkläre ich verständlich in meinem Beitrag TCP Window Size und Window Scaling einfach erklärt.
9. SYN ohne Antwort: Wenn der Server schweigt
tcp.flags.syn == 1 && tcp.flags.ack == 0
Filtert Verbindungsversuche (SYN), auf die keine Bestätigung (SYN-ACK) folgt.
Profi-Hinweis zur Syntax: Du findest im Netz oft die Variante !tcp.flags.ack == 1. Die funktioniert bei Flags zwar, ist aber schlechte Angewohnheit – bei Feldern wie ip.addr führt dieselbe Schreibweise zu falschen Ergebnissen (siehe Filter 2). Gewöhn dir == 0 bzw. die geklammerte Negation an, dann passiert dir das nie.
Diagnose: Der Klassiker für „Server nicht erreichbar”. Du siehst das SYN, aber kein SYN-ACK kommt zurück – entweder verwirft eine Firewall das Paket oder der Ziel-Host ist im Netz gerade nicht vorhanden. Sicherer Beweis für Firewall-Blocker oder Routing-Probleme. Wie der TCP-Handshake im Detail funktioniert und was jede Abweichung bedeutet, habe ich in einem eigenen Grundlagenartikel beschrieben. Bleiben SYN-Pakete dauerhaft unbeantwortet, mündet das in Connection Timeouts – wie solche Verbindungsabbrüche zu analysieren und einzugrenzen sind, zeige ich in einem eigenen Beitrag.
10. Paket-Inhalte durchsuchen
Manchmal muss man tiefer graben. Dieser Filter durchsucht die gesamte Payload der Pakete nach einem bestimmten String.
Wichtiger Hinweis: Funktioniert nur bei unverschlüsseltem Verkehr (HTTP, SMTP, altes SQL). Bei TLS-Traffic siehst du nur Zeichensalat – es sei denn, du hinterlegst die Session-Keys in Wireshark über die SSLKEYLOGFILE-Variable. Wie viel selbst im verschlüsselten Verkehr noch sichtbar ist – etwa Zertifikatsdetails im TLS-Handshake – zeigt eindrucksvoll mein Praxisfall zu TLS-Zertifikatsfehlern in einer VoIP-Umgebung: Dort verriet Wireshark die Fehlerursache, während die Konsole des Systems komplett schwieg.
Bonus: Der Alles-auf-einen-Blick-Filter
tcp.analysis.flags && !tcp.analysis.window_update
Wenn du einen unbekannten Trace zum ersten Mal öffnest und schnell wissen willst, ob überhaupt etwas im Argen liegt: Dieser Filter zeigt dir alle Pakete, die Wireshark selbst als auffällig markiert hat – Retransmissions, Duplicate ACKs, Zero Windows, Out-of-Order und mehr. Die Window Updates blenden wir aus, weil sie normal und harmlos sind. Mein Standard-Einstieg in fast jede Analyse: Ist die Trefferliste leer, liegt das Problem sehr wahrscheinlich nicht auf TCP-Ebene – und du sparst dir stundenlanges Suchen am falschen Ort.
Die drei häufigsten Ursachen in meinen Projekten
Duplex-Mismatch / defekte Kabel führen zu massiven Paketverlusten und CRC-Fehlern – Wireshark zeigt viele Retransmissions ohne klare Richtung. Wie du solche Paketverluste sauber lokalisierst und von anderen Ursachen abgrenzt, zeigt mein Packet-Loss-Guide.
Überlastete Sicherheits-Appliances: Firewalls mit Deep Packet Inspection werden zum Bottleneck, wenn der Durchsatz steigt. Erkennbar durch steigende tcp.time_delta-Werte, die sich an der Firewall-IP häufen – kombiniert mit sporadischen Verbindungsabbrüchen, die auf den ersten Blick keinem klaren Muster folgen.
Fehlkonfiguriertes MTU: Wenn Pakete zu groß für einen VPN-Tunnel sind und nicht fragmentiert werden dürfen, verschwinden sie einfach – ohne Fehlermeldung. Einer der frustrierendsten Fehler im WAN-Umfeld, der sich oft als scheinbar zufälliger Paketverlust tarnt.
Genau solche Fälle analysiere ich für Unternehmen – auf Paketebene, mit belastbaren Beweisen statt Vermutungen. Häufig ist die Ursache nach einem Analysetag eingegrenzt, wo intern bereits wochenlang gesucht wurde. Wie eine Zusammenarbeit typischerweise abläuft, liest du am Ende dieses Artikels.
Best Practices für den professionellen Wireshark-Einsatz
An der richtigen Stelle mitschneiden: Bei Problemen zwischen Client und Server idealerweise an beiden Enden gleichzeitig mitschneiden. So erkennst du sofort, ob ein Paket unterwegs verloren ging oder vom Empfänger ignoriert wurde.
Coloring Rules nutzen: Wireshark färbt Pakete standardmäßig ein. Passe diese Regeln an deine häufigsten Filter an – so erkennst du kritische Muster auf einen Blick, ohne aktiv filtern zu müssen.
Im Zweifel alles aufzeichnen: Wie im Abschnitt zu Capture Filtern beschrieben – zu viele Daten lassen sich eingrenzen, zu wenige nicht rekonstruieren. Gerade bei sporadischen Problemen oder unklarer Fehlerursache ist ein vollständiger Mitschnitt Gold wert.
Baseline aufnehmen: Mache eine Netzwerkanalyse, wenn alles ruhig läuft. Nur wer den Normalzustand seines Netzes kennt, kann Abweichungen im Fehlerfall sicher als Problem identifizieren. Was dabei alles zu beachten ist, beschreibe ich in meinem Überblick zur Wireshark-Netzwerkanalyse.
Fazit: Datenbasiert entscheiden statt auf Verdacht handeln
Wireshark ist kein Tool, das man nebenbei lernt – es erfordert Übung und ein solides Verständnis der Protokolle. Aber es ist die einzige Wahrheit im Netz. Wer die zehn Filter aus diesem Artikel beherrscht, kann 80 % der gängigen Performance-Probleme innerhalb weniger Minuten eingrenzen – und vor allem: mit Belegen argumentieren statt zu raten. Das beendet nicht nur die Fehlersuche schneller, sondern auch das Fingerpointing zwischen Teams.
Meine Empfehlung: Warte nicht auf den nächsten Notfall. Installiere Wireshark in einer Testumgebung, ruf eine Webseite auf und probiere die Filter aus. Schau dir an, wie ein normaler TCP-Verbindungsaufbau aussieht – dann erkennst du Abweichungen sofort. Einen guten Einstieg in den gesamten Analyse-Workflow bietet mein Beitrag zur Wireshark-Netzwerkanalyse für Performance-Fehler. Wie so eine Analyse in echten Projekten aussieht – inklusive Traces, Denkweise und Ergebnis – zeigen meine Praxisfälle zum N+1-Query-Muster und zu TLS-Zertifikatsfehlern im VoIP-Umfeld.
Und wenn du gerade mitten in so einem Fall steckst – das Problem ist reproduzierbar, aber die Ursache bleibt trotz aller Filter im Dunkeln, oder Netzwerk- und Applikationsteam schieben sich seit Wochen die Verantwortung zu: Genau dafür findest du direkt unter diesem Artikel den Weg zu mir.
FAQ – Häufig gestellte Fragen
1. Warum sehe ich so viele „Checksum Errors” in Wireshark?
Das liegt meist am TCP Checksum Offloading: Die Netzwerkkarte berechnet die Prüfsumme erst beim Versenden, Wireshark fängt das Paket jedoch vorher ab. In den meisten Fällen kein echtes Netzwerkproblem, sondern ein Artefakt der Messung. Du kannst die Prüfsummenvalidierung in den Wireshark-Einstellungen deaktivieren, um die Ansicht zu bereinigen.
2. Kann Wireshark auch verschlüsselten HTTPS-Traffic lesen?
Ja – aber nur unter bestimmten Voraussetzungen. Du benötigst entweder den SSL/TLS-Schlüssel des Servers oder kannst bei Browser-Traffic die SSLKEYLOGFILE-Variable nutzen, um Session-Keys zu exportieren und in Wireshark einzubinden.
3. Wo platziere ich den Analyse-Rechner am besten?
Am besten an einem Mirror-Port (SPAN-Port) deines Switches, der den gesamten Traffic des Ziel-Ports auf deinen Rechner spiegelt. Alternativ funktioniert ein Netzwerk-TAP, der physisch in die Leitung eingeschleift wird und den Datenverkehr passiv abgreift – ohne den Netzwerkbetrieb zu beeinflussen. Welche Platzierung für welches Szenario sinnvoll ist, erkläre ich auch in meinem Überblick zur strukturierten Netzwerkanalyse mit Wireshark.
4. Wann lohnt sich externe Unterstützung bei der Netzwerkanalyse?
Als Faustregel: Wenn ein Problem trotz interner Analyse länger als ein bis zwei Wochen ungelöst bleibt, mehrere Teams sich gegenseitig die Verantwortung zuschieben oder geschäftskritische Anwendungen betroffen sind. Die Kosten eines externen Analysetages sind fast immer deutlich geringer als die Produktivitätsverluste durch ein wochenlang ungelöstes Performance-Problem – vom internen Aufwand für Trial-and-Error-Maßnahmen ganz zu schweigen.