
Wie lese ich einen TCP Stream richtig? – Schritt für Schritt mit Wireshark
Wer schon mal eine Wireshark-Aufzeichnung geöffnet hat und auf Tausende von Paketen gestarrt hat, kennt das Gefühl: Wo fange ich überhaupt an? Die einzelnen Pakete sagen dir zwar viel – aber erst im Zusammenhang ergibt sich das vollständige Bild. Genau dafür gibt es die Stream-Analyse. Und wenn du lernst, TCP Streams wirklich zu lesen – nicht nur zu öffnen – wirst du Fehlerquellen finden, die in der Paketliste schlicht unsichtbar bleiben.
In diesem Artikel zeige ich dir, wie du systematisch vorgehst: vom ersten Rechtsklick bis zur Latenz-Messung und der richtigen Interpretation von FIN und RST. Mit Beispielen aus der Praxis, nicht aus dem Lehrbuch.
Was ist ein TCP Stream und warum ist er so wichtig?
Ein TCP Stream ist keine eigene Datenstruktur – er ist eine logische Zusammenfassung aller Pakete, die zu einer einzelnen TCP-Verbindung gehören. Wireshark identifiziert diese Verbindung anhand des sogenannten 5-Tupels: Quell-IP, Ziel-IP, Quellport, Zielport und Protokoll (TCP). Jede eindeutige Kombination dieser fünf Werte bekommt von Wireshark eine eigene Stream-ID – beginnend bei 0.
In der Paketliste siehst du diese ID in der Spalte tcp.stream, falls du sie eingeblendet hast. Aber das ist nur der Einstieg. Der eigentliche Wert der Stream-Perspektive liegt darin, dass du den Datenfluss als Ganzes bewertest – nicht einzelne Pakete isoliert.
Stell dir vor, du untersuchst ein Performance-Problem: Eine Anwendung lädt langsam, die Nutzer beschweren sich. In der Paketliste siehst du TCP-Retransmissions. Auf den ersten Blick sieht das nach Paketverlust aus. Schaust du aber in den Stream, erkennst du vielleicht, dass zwischen Request und Response eine ungewöhnlich lange Pause liegt – und die Retransmission nur eine Folgereaktion ist. Einzelne Pakete lügen, der Stream erzählt die Wahrheit.
„Follow TCP Stream” – der erste Schritt
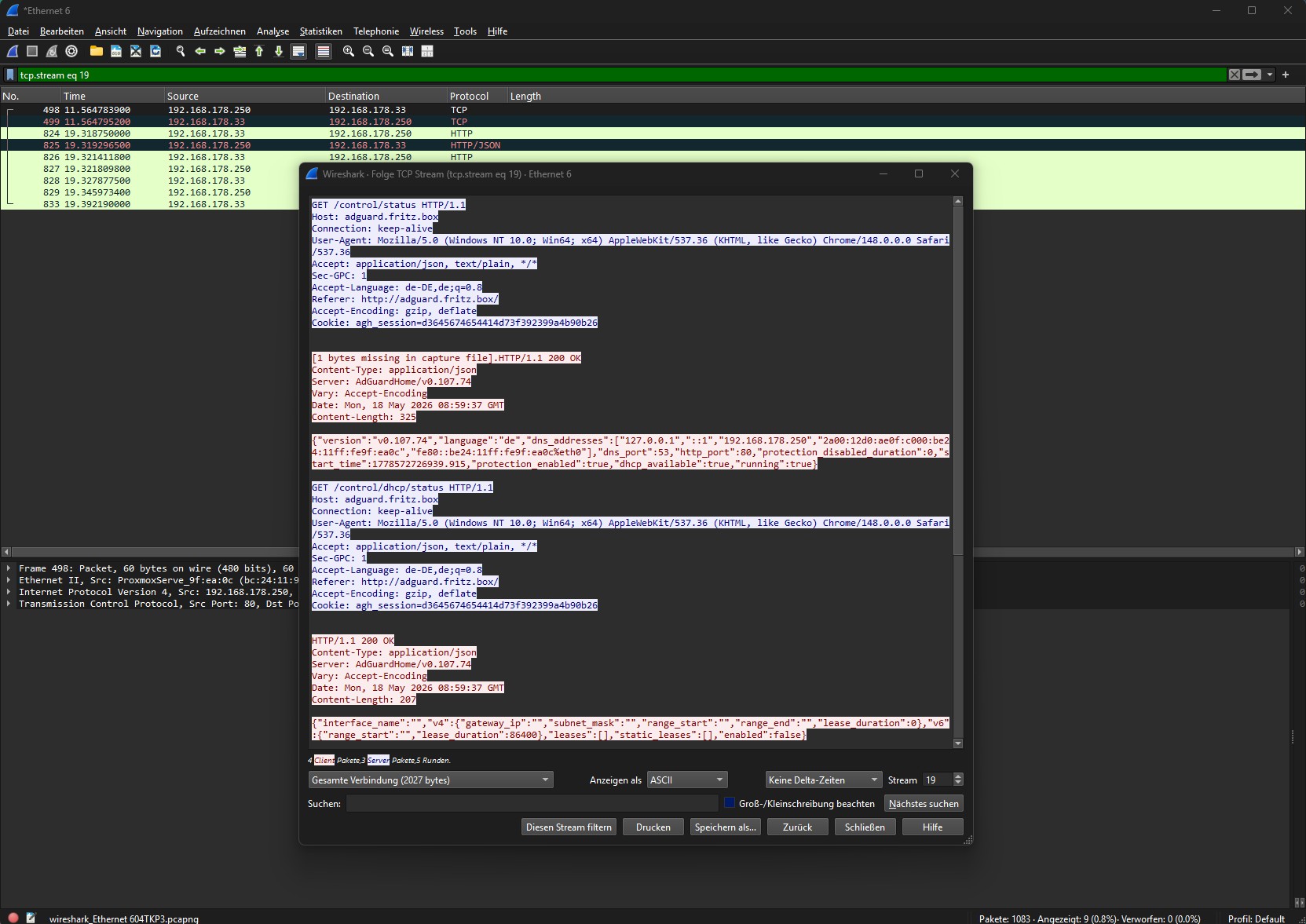
Der einfachste Einstieg in die Stream-Analyse ist die Funktion „Follow TCP Stream”. Du erreichst sie per Rechtsklick auf ein beliebiges Paket der Verbindung, die dich interessiert – dann Follow → TCP Stream. Wireshark filtert daraufhin automatisch alle Pakete dieses Streams und öffnet ein separates Fenster mit dem rekonstruierten Datenstrom.
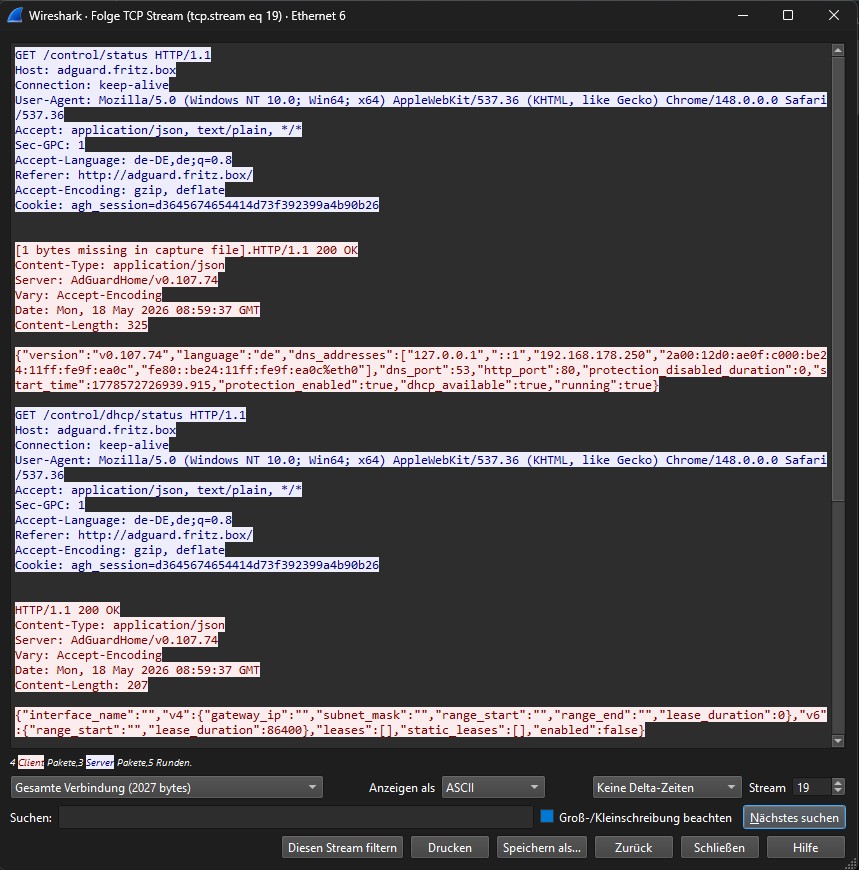
Im Dialogfenster siehst du zwei Farben:
- Rot steht für den Traffic vom Client zum Server (Anfragen, Uploads, Kommandos).
- Blau steht für den Traffic vom Server zum Client (Antworten, Daten, Fehlermeldungen).
Du kannst die Ansicht zwischen ASCII und Raw umschalten. ASCII ist ideal für Klartext-Protokolle wie HTTP, SMTP oder FTP – du siehst Header, Anfragen und Antworten direkt im Klartext. Raw zeigt dir die Hex-Bytes, was bei binären oder verschlüsselten Protokollen relevant wird, auch wenn du dort ohne den Schlüssel wenig anfangen kannst.
In diesem Beispiel siehst du einen Aufruf von einer HTTP Webseite. Der Benutzer stellt einen HTTP Request auf die URI /control/status des Webserver adguard.fritz.box :
Ein praktischer Nebeneffekt: Wireshark setzt nach dem „Follow”-Aufruf automatisch einen Display-Filter auf den jeweiligen Stream. Den kannst du ablesen, manuell anpassen und für weitere Analysen nutzen. Wenn du mit Display-Filtern noch nicht vertraut bist, lohnt sich ein Blick in meinen Artikel zu den 10 wichtigsten Wireshark Display-Filtern.
Sequenznummern & ACKs im Stream verstehen
Sobald du im Stream bist, wird es technisch – und genau hier trennt sich die oberflächliche Paket-Betrachtung von echter Analyse. TCP ist ein verbindungsorientiertes, sequenzbasiertes Protokoll. Jedes Byte, das über eine TCP-Verbindung übertragen wird, hat eine Sequenznummer. Der Empfänger bestätigt den Empfang mit einem ACK, der die nächste erwartete Sequenznummer enthält.
In Wireshark arbeitet man meistens mit den relativen Sequenznummern – die beginnen bei 0, was die Lesbarkeit deutlich erhöht. Du kannst das unter Edit → Preferences → Protocols → TCP einstellen, falls es nicht bereits aktiv ist.
Den Datenfluss ablesen
In der Paketliste erkennst du am Zusammenspiel von Seq- und ACK-Nummern, wie Daten fließen. Ein einfaches Beispiel:
| Richtung | Seq | ACK | Len | Bedeutung |
|---|---|---|---|---|
| Client → Server | 0 | – | 120 | Request mit 120 Byte Payload |
| Server → Client | 0 | 120 | 0 | ACK: „120 Byte erhalten, weiter” |
| Server → Client | 0 | 120 | 1460 | Erste Antwort mit 1460 Byte |
| Client → Server | 120 | 1460 | 0 | ACK: „1460 Byte erhalten” |
Das ist der Normalzustand. Wenn du dieses Muster erkennst und es gleichmäßig weiterläuft, ist der Stream gesund.
Was ein Gap in den Sequenznummern bedeutet
Kritisch wird es, wenn Sequenznummern springen. Du erwartest Seq 1460, aber das nächste Paket hat Seq 2920 – ohne dass ein Paket mit Seq 1460 bis 2920 sichtbar ist. Das ist ein Gap. In den meisten Fällen bedeutet das: Ein Paket fehlt in der Aufzeichnung – entweder weil es verloren gegangen ist, oder weil dein Capture-Punkt es nicht gesehen hat.
Gaps sind heimtückisch, weil sie oft nicht sofort als Problem erkennbar sind. Mehr dazu, wie du echten Paketverlust von Capture-Artefakten unterscheidest, habe ich in meinem Artikel zu Packet Loss messen – warum Pings oft lügen beschrieben.
Retransmission, Reorder und Dup ACKs
Wireshark markiert viele dieser Anomalien automatisch – in der Spalte Info tauchen dann Einträge wie [TCP Retransmission], [TCP Out-Of-Order] oder [TCP Dup ACK] auf. Was diese Markierungen genau bedeuten und wie du sie richtig interpretierst, erkläre ich ausführlich in meinem Artikel TCP Retransmissions, Dup ACKs & Out-of-Order – Unterschiede.
Kurz zusammengefasst: Retransmissions sind immer ein Zeichen, dass etwas nicht angekommen ist. Aber sie sind nicht die Ursache – sie sind die Reaktion. Die Ursache liegt woanders: im Netz, in der Anwendung oder im Betriebssystem.
Dass Retransmissions mehr Auswirkung auf die Performance haben als viele denken, zeige ich auch in meinem Artikel TCP Retransmissions: Der stille Performance-Killer.
Wo steckt die Latenz? RTT im Stream ablesen
Einer der häufigsten Anlässe für eine Stream-Analyse ist die Frage: „Warum ist die Anwendung so langsam?” Und die Antwort liegt fast immer in der Latenz-Struktur des Streams – nicht in einzelnen Paketen.
Zeit zwischen Request und Response messen
Das Werkzeug der Wahl ist die Zeitdifferenz zwischen Paketen. Dafür gibt es in Wireshark mehrere Möglichkeiten:
- Delta-Zeit (Zeit seit dem letzten Paket) – in den Spaltenoptionen als
frame.time_deltahinzufügbar - Zeitstempel relativ zum Stream-Start – zeigt, wie lange es ab dem Verbindungsaufbau bis zu einem bestimmten Paket dauert
- TCP-RTT – Wireshark berechnet die Round-Trip-Time automatisch, wenn du im Paket-Detail unter TCP → Analysis → iRTT nachschaust
Der praktischste Ansatz: Klick auf das Paket mit dem Request (z.B. HTTP GET), dann schau, welches Paket die Antwort enthält, und lies die Zeitdifferenz ab. In einer lokalen Umgebung erwartest du wenige Millisekunden. Über eine WAN-Strecke können es 30–80 ms sein – das ist normal. Alles darüber ist ein Warnsignal.
Unterschied: Netzwerklatenz vs. Server-Verarbeitungszeit
Hier liegt einer der häufigsten Denkfehler in der Praxis: Nicht jede Verzögerung im Stream ist Netzwerklatenz. Wireshark misst Zeiten auf dem Kabel – aber die Zeit, die ein Server braucht, um eine Antwort zu berechnen, siehst du auch im Stream. Du musst also unterscheiden:
- Netzwerklatenz: Zeit, die ein Paket braucht, um von A nach B zu kommen. Erkennbar an symmetrischer Verzögerung in beide Richtungen, klassisch messbar über den TCP-Handshake (SYN → SYN/ACK). Mehr dazu in meinem Artikel zum TCP Handshake analysieren mit Wireshark.
- Server-Verarbeitungszeit: Zeit zwischen dem letzten eingehenden Request-Paket (ACK vom Server) und dem ersten Antwort-Paket. Diese Zeit liegt vollständig auf der Server-Seite.
Wenn du clientseitig mitschneidest und zwischen dem letzten Request-Paket und dem ersten Antwort-Paket eine große Lücke siehst – größer als die bekannte Netzwerk-RTT – dann ist der Server das Problem, nicht das Netz.
Praxisbeispiel: HTTP-Request über WAN-Strecke
In einem Kundenprojekt bei einem mittelständischen Fertigungsunternehmen haben wir genau dieses Muster gesehen: Eine webbasierte ERP-Anwendung war über eine 50-Mbit-MPLS-Strecke angebunden. Die Nutzerbeschwerden lauteten klassisch: „Die Anwendung hängt.” Die Netzwerkabteilung zeigte auf den Auslastungsgrafen – keine Überlastung. Der Server-Administrator zeigte auf den CPU-Monitor – auch unauffällig.
Im TCP Stream haben wir Folgendes gesehen: Netzwerk-RTT laut Handshake ca. 18 ms. Zeit zwischen Request und erster Response: 1,4 Sekunden. 1,4 Sekunden, die vollständig auf dem Server lagen. Das Netz war nicht das Problem – die Anwendungslogik war es. Erst mit diesem Nachweis aus dem Trace war die Diskussion beendet.
Häufige Fehler beim Lesen von TCP Streams
Stream-Analyse klingt methodisch – ist es auch. Aber es gibt klassische Denkfallen, in die selbst erfahrene Analysten gelegentlich tappen.
Falsche Schlüsse aus einzelnen Paketen ziehen
Ein einzelnes Paket mit dem Flag [RST] sieht dramatisch aus. Aber ohne Kontext aus dem Stream weißt du nicht, ob das ein normales Connection-Teardown nach Abschluss der Übertragung ist, oder ob eine Seite die Verbindung unerwartet gekappt hat. Immer den Stream als Ganzes lesen, bevor du eine Aussage triffst.
Capture-Seite vergessen
Das ist vielleicht der häufigste Fehler überhaupt: Du siehst etwas im Trace – und vergisst dabei, von wo aus du schaust. Retransmissions, die du clientseitig siehst, können vom Server stammen. Delays können durch Middleware verursacht werden, die du gar nicht im Blick hast. Immer dokumentieren: Wo wurde aufgezeichnet, und was liegt zwischen den Endpunkten?
FIN und RST falsch interpretieren
FIN bedeutet: „Ich bin fertig mit Senden.” Es ist ein geordnetes Ende – und völlig normal. RST hingegen bedeutet: „Verbindung sofort beenden, ohne Handshake.” Das kann ein Fehler sein – muss es aber nicht. Firewalls setzen RST aktiv ein, Load Balancer auch. Mehr dazu, wie du das richtig auseinanderhältst, findest du in meinem Artikel zu Verbindungsabbrüchen analysieren mit Wireshark.
Window Size ignorieren
Die TCP Window Size bestimmt, wie viel Daten der Empfänger bereit ist zu empfangen, bevor er ein ACK sendet. Sinkt die Window Size im Stream rapide – bis hin zu Zero-Window-Meldungen – ist das ein klares Zeichen für einen überlasteten Empfänger. Das passiert oft bei langsamen Applikationsservern oder überlasteten Clients. Das Thema erkläre ich ausführlich in meinem Artikel zur TCP Window Size & Scaling.
Wann reicht ein Stream – und wann brauchst du mehr?
Die Stream-Analyse ist ein hervorragender Einstiegspunkt – aber sie ist kein Allheilmittel. Es gibt Situationen, in denen du mit einem einzelnen Stream-Follow nicht weiterkommst:
Wann der Stream ausreicht
- Du willst eine einzelne Verbindung bewerten: Läuft sie sauber durch? Gibt es Retransmissions? Wie hoch ist die Latenz?
- Du willst prüfen, was eine Anwendung tatsächlich über das Netz sendet (Protokoll-Debugging).
- Du willst die Server-Verarbeitungszeit vom Netz abgrenzen.
Wann du mehr brauchst
- Viele parallele Verbindungen: Moderne Anwendungen nutzen Connection Pooling, HTTP/2 Multiplexing oder mehrere TCP-Sessions gleichzeitig. Ein einzelner Stream zeigt dir nur einen Bruchteil davon. Hier brauchst du eine aggregierte Analyse – z.B. über Statistics → TCP Stream Graphs → Throughput oder Conversations.
- Serverseitiger Kontext fehlt: Du siehst clientseitig Delays, aber du kannst nicht sagen, ob der Server die Requests überhaupt rechtzeitig verarbeitet hat. Dann brauchst du einen serverseitigen Capture – am besten zeitgleich mit dem clientseitigen Trace, um Timestamps vergleichen zu können.
- Verschlüsselter Traffic: TLS-verschlüsselte Verbindungen kannst du im Stream sehen, aber nicht lesen. Für eine tiefere Analyse brauchst du Schlüsseldaten (SSLKEYLOGFILE) oder du musst auf Protokollebene des Servers arbeiten.
- Intermittierende Probleme: Wenn das Problem nur sporadisch auftritt, reicht ein einzelner Stream nicht aus. Du brauchst einen Langzeit-Capture oder eine kontinuierliche Aufzeichnung mit Ringbuffer.
Die Stream-Analyse ist also der erste Schritt einer Diagnose, nicht das Ergebnis. Sie zeigt dir, wo du tiefer graben musst – und spart dir dabei die blinde Suche durch Tausende von Paketen.
Fazit
Einen TCP Stream richtig zu lesen ist eine Fähigkeit, die man sich erarbeitet – nicht durch das Auswendiglernen von Flags und Feldern, sondern durch das systematische Anschauen echter Verbindungen. Mit der Zeit entwickelst du ein Gespür dafür, wie ein gesunder Stream aussieht – und erkennst sofort, wenn etwas nicht stimmt.
Die wichtigsten Punkte aus diesem Artikel noch einmal zusammengefasst:
- Streams identifiziert Wireshark anhand des 5-Tupels – immer als Erstes prüfen, welchen Stream du analysierst.
- „Follow TCP Stream” ist dein Einstieg, kein Endpunkt – nutze die Farben und die ASCII-Ansicht zur schnellen Orientierung.
- Sequenznummern und ACKs erzählen den Datenfluss – Gaps, Sprünge und Wiederholungen sind Warnsignale.
- Latenz setzt sich zusammen aus Netzwerk-RTT und Server-Verarbeitungszeit – beides musst du im Stream auseinandernehmen können.
- FIN ist normal, RST ist kontextabhängig – nie ohne Blick auf den Gesamtverlauf bewerten.
- Ein Stream reicht nicht immer – manchmal brauchst du serverseitige Captures, parallele Traces oder eine aggregierte Sicht.
Wenn du nach diesem Artikel deine nächste Wireshark-Aufzeichnung öffnest, weißt du, wo du anfängst – und was du suchst. Und wenn du merkst, dass die Stream-Analyse alleine nicht ausreicht, weißt du auch, wann es Zeit ist, tiefer zu graben.
Hast du Fragen zu einer konkreten Situation oder einem spezifischen Trace? Schreib mir gern – solche Praxisfälle sind genau das, womit ich in meiner täglichen Arbeit zu tun habe.