
Congestion Control: Wie TCP Reno, CUBIC und BBR den Datendurchsatz steuern
Inhaltsverzeichnis
ToggleWas ist TCP Congestion Control – und warum ist es wichtig?
TCP ist ein zuverlässiges Protokoll – es sorgt dafür, dass Daten vollständig und in der richtigen Reihenfolge ankommen. Aber Zuverlässigkeit allein reicht nicht. Würde jeder TCP-Sender so schnell senden wie möglich, würden Netzwerke sofort kollabieren. Genau hier kommt Congestion Control ins Spiel. Das Grundprinzip: TCP verwaltet intern ein sogenanntes Congestion Window (CWND) – eine dynamische Obergrenze dafür, wie viele Daten gleichzeitig „im Flug” sein dürfen. Dieses Fenster wird laufend angepasst, abhängig davon, wie das Netzwerk gerade reagiert.Slow Start
Zu Beginn einer Verbindung kennt TCP die verfügbare Bandbreite nicht. Es startet deshalb konservativ – mit einem kleinen CWND – und verdoppelt es pro Round Trip, solange keine Probleme auftreten. Das klingt langsam, führt aber in der Praxis zu einem exponentiellen Anstieg. Bei kurzen Verbindungen (z. B. HTTP-Requests) verbringt TCP einen erheblichen Teil seiner Lebenszeit im Slow Start.Additive Increase, Multiplicative Decrease (AIMD)
Sobald ein Schwellwert (Slow Start Threshold, ssthresh) erreicht ist, wechselt TCP in die Congestion Avoidance: Das Fenster wächst jetzt nur noch linear – pro RTT um ein Segment. Erkennt TCP ein Überlastungssignal (typischerweise Paketverlust), wird das Fenster drastisch reduziert. Dieses Prinzip heißt Additive Increase, Multiplicative Decrease (AIMD) und ist das Fundament aller klassischen Algorithmen. Warum das für dich relevant ist: Welcher Algorithmus den AIMD-Zyklus steuert, bestimmt direkt, wie schnell deine Verbindung nach einem Einbruch wieder auf Touren kommt. Auf einer LAN-Strecke mit 1 ms RTT ist das kaum spürbar. Auf einer WAN-Verbindung mit 80 ms RTT kann es den Unterschied zwischen 50 Mbit/s und 500 Mbit/s bedeuten – bei identischer physischer Bandbreite. Zur Vertiefung, wie CWND und Window Size zusammenspielen, empfehle ich den Artikel TCP Window Size & Scaling einfach erklärt.TCP Reno – der Klassiker unter den Congestion-Algorithmen
TCP Reno ist alt. Sehr alt. Entwickelt in den späten 1980ern, war es jahrzehntelang der Standardalgorithmus auf nahezu allen Betriebssystemen. Und er funktioniert – solange die Randbedingungen stimmen.Funktionsprinzip
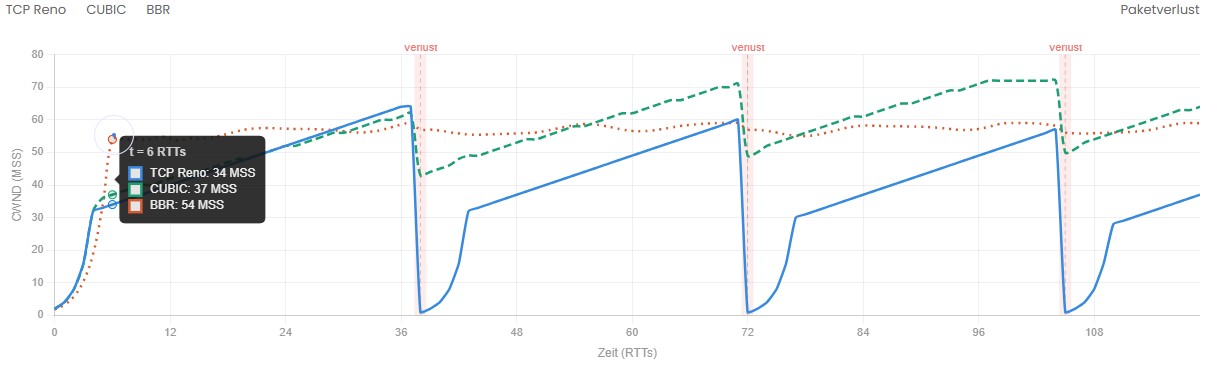
Reno arbeitet rein verlustbasiert: Paketverlust ist das einzige Signal, das es zur Erkennung von Netzwerküberlastung nutzt. Erkennt Reno drei duplizierte ACKs (Fast Retransmit), halbiert es das CWND. Bei einem Timeout – dem härteren Verlustereignis – geht es sogar zurück in den Slow Start. Danach steigt das Fenster wieder linear an. Das Ergebnis ist das bekannte Sägezahnmuster (Sawtooth Pattern): CWND wächst stetig, bricht dann abrupt ein, wächst wieder. Im Wireshark-Trace ist dieses Muster gut erkennbar – dazu gleich mehr.Wo Reno an Grenzen stößt
Das klassische Problem von Reno ist das Bandwidth-Delay-Product (BDP). Bei hoher Bandbreite und hoher Latenz muss das CWND sehr groß werden, um die Leitung auszulasten. Nach jedem Paketverlust bricht Reno das Fenster auf die Hälfte ein – und braucht bei 100 ms RTT viele Sekunden, um es wieder aufzubauen. Auf modernen Hochgeschwindigkeitsnetzen oder WAN-Verbindungen ist Reno deshalb hoffnungslos ineffizient. In einem Projekteinsatz bei einem Industriekunden mit einem 10-Gbit/s-Backbone und mehreren Standortverbindungen über Richtfunk (Latenzen 30–60 ms) haben wir genau dieses Phänomen beobachtet: Der Durchsatz im File-Transfer lag bei unter 10 % der theoretischen Kapazität – nicht wegen der Hardware, sondern wegen Reno.CUBIC – der Linux-Standard für Hochgeschwindigkeitsnetze
CUBIC ist seit Linux-Kernel 2.6.19 (2006) der Standard-Congestion-Control-Algorithmus unter Linux – und damit auf dem Großteil der Serversysteme, die heute im Einsatz sind. Er wurde entwickelt, um genau das Problem zu lösen, das Reno auf schnellen Verbindungen hat.Der Cubic-Growth-Ansatz
Anstatt das CWND nach einem Verlust linear aufzubauen, nutzt CUBIC eine kubische Funktion, die sich am Zeitpunkt des letzten Verlustes orientiert. Das Fenster wächst zunächst schnell, verlangsamt sich dann in der Nähe des vorherigen Maximums (um Überlastung zu vermeiden), und beschleunigt danach wieder, wenn kein neuer Verlust auftritt. Der entscheidende Unterschied: CUBIC baut das Fenster zeitbasiert auf, nicht RTT-basiert. Das bedeutet, Verbindungen mit hoher Latenz werden nicht systematisch benachteiligt – CUBIC verhält sich bei 200 ms RTT ähnlich wie bei 20 ms RTT, was Reno nicht schafft.Stärken und Schwächen von CUBIC
Stärken: Sehr gute Performance auf Hochgeschwindigkeitsnetzen (10G, 100G), faire Koexistenz mit anderen CUBIC-Flows, gut erforscht und stabil. Schwächen: CUBIC ist immer noch verlustbasiert. Es reagiert auf Paketverlust – und damit auch auf Verlust, der nicht durch Überlastung, sondern durch Leitungsqualität verursacht wird (z. B. WLAN, LTE, Satellitenstrecken). Auf solchen Strecken drosselt es sich unnötigerweise. Außerdem kann CUBIC auf sehr kurzen, hochbandbreitigen Verbindungen (z. B. Rechenzentrum intern) aggressiver sein als nötig, was zu Fairness-Problemen bei vielen parallelen Flows führt.BBR – Googles Ansatz: Modellbasiert statt verlustbasiert
BBR (Bottleneck Bandwidth and Round-trip propagation time) ist 2016 von Google entwickelt worden – und es ist ein Paradigmenwechsel. Statt auf Paketverlust zu reagieren, versucht BBR, das Netzwerk aktiv zu modellieren.Der Paradigmenwechsel: Modellbasierte Steuerung
BBR misst kontinuierlich zwei Größen: die maximale beobachtete Bandbreite (BtlBw) und die minimale beobachtete RTT (RTprop). Aus diesen beiden Werten leitet es den Arbeitspunkt ab, an dem die Leitung optimal ausgenutzt ist, ohne die Puffer zu füllen. BBR sendet nicht mehr als das Netzwerk transportieren kann – und füllt keine Puffer. Das klingt elegant, und es ist es auch. BBR leidet nicht unter dem klassischen Sawtooth-Problem, weil es Paketverlust nicht als primäres Congestion-Signal nutzt. Verlust auf einer schlechten WLAN-Strecke führt also nicht automatisch zur Drosselung. Gerade deswegen lohnt ein Blick auf den Artikel Packet Loss messen – warum Pings oft lügen – denn BBR zeigt exemplarisch, warum Paketverlust allein kein zuverlässiges Überlastungssignal ist.BBR in der Praxis: WAN und Cloud
In Cloud-Umgebungen, auf WAN-Strecken mit hoher Latenz und auf Verbindungen mit gelegentlichem, nicht-kongestivem Verlust (z. B. Mobilfunk) zeigt BBR deutliche Vorteile. Google hat BBR auf seinen Servern eingesetzt und über YouTube-Verbindungen messbare Durchsatzsteigerungen – teils mehr als Faktor 10 auf bestimmten Strecken – berichtet.Fairness-Probleme in gemischten Umgebungen
Hier wird es kritisch: BBR und CUBIC spielen nicht gut zusammen. In einer Umgebung, in der BBR- und CUBIC-Flows dieselbe Flaschenhals-Verbindung teilen, kann BBR einen unverhältnismäßig großen Anteil der Bandbreite beanspruchen. BBR ist nicht zwingend fair gegenüber verlustbasierten Algorithmen. Das ist in homogenen Umgebungen kein Problem – sobald aber gemischte Client-Populationen auf denselben Upstream treffen, kann es zu Fairness-Problemen kommen. Der Vergleich verlustbasierter vs. modellbasierter Erkennung ist auch ein zentrales Thema im Artikel TCP Retransmissions, Dup ACKs & Out-of-Order – Unterschiede.Direkter Vergleich: Reno vs. CUBIC vs. BBR – wann lohnt sich was?
| Algorithmus | Ansatz | Typisches Einsatzszenario | Stärke | Schwäche |
|---|---|---|---|---|
| TCP Reno | Verlustbasiert, lineares AIMD | LAN, kurze Verbindungen, Legacy-Systeme | Stabil, gut verstanden, fair | Ineffizient bei hohem BDP (WAN, High-Speed) |
| CUBIC | Verlustbasiert, kubisches Wachstum | Linux-Server, Datacenter, Standard-WAN | Sehr gute Performance auf schnellen Leitungen, RTT-unabhängig | Reagiert auf nicht-kongestiven Verlust, Fairness-Probleme möglich |
| BBR | Modellbasiert (BtlBw + RTprop) | Cloud, WAN mit hoher Latenz, Mobilfunk, heterogene Verbindungen | Kein Sawtooth, robust gegen nicht-kongestiven Verlust, hoher Durchsatz auf langen Strecken | Fairness-Probleme mit CUBIC/Reno, Puffer-Interaktion komplex |
TCP Reno
Sawtooth-Pattern
Linearer Wiederaufbau nach Verlust – langsam auf WAN-Strecken
CUBIC
Kubische Kurve
Schnellere Erholung, zeitbasiert – Linux-Standard seit 2006
BBR
Stabile Bandbreite
Kein Einbruch bei Verlust – modellbasiert, kein Sawtooth
Was du im Wireshark-Trace siehst – Congestion Control erkennbar machen
Congestion Control ist kein abstraktes Konzept – du kannst es im Paketmitschnitt direkt beobachten. Der wichtigste Ausgangspunkt ist der TCP Stream Graph in Wireshark.CWND-Verhalten und das Sawtooth-Pattern
Öffne einen TCP-Stream in Wireshark und gehe auf Statistics → TCP Stream Graphs → Time/Sequence (tcptrace). Hier siehst du die gesendeten Sequenznummern über die Zeit. Bei einem verlustbasierten Algorithmus wie Reno oder CUBIC erkennst du das charakteristische Sägezahnmuster: gleichmäßiges Wachstum, dann ein steiler Absturz nach einem Verlustereignis, gefolgt vom nächsten Aufbau. Bei BBR sieht das deutlich anders aus: Der Graph ist in der Regel glatter, ohne die starken Einbrüche. BBR füllt die Leitung gleichmäßiger und reagiert nicht auf jeden einzelnen Verlust mit einer Drosselung.RTT-Verlauf analysieren
Der Round Trip Time Graph (Statistics → TCP Stream Graphs → Round Trip Time) zeigt dir, wie sich die Latenz über die Zeit verhält. Stark schwankende RTT-Werte in Kombination mit Retransmissions sind ein klassisches Zeichen für Puffer-Überlauf – sogenanntes Bufferbloat. Hier zeigt sich auch der Unterschied zwischen CUBIC (das Puffer füllt) und BBR (das versucht, Puffer leer zu halten).Praxistipp: io.stat und TCP-Stream-Graphs
Mitio.stat kannst du Durchsatz und Verlustrate über Zeitintervalle aggregieren. Kombiniert mit dem TCP-Stream-Graph bekommst du ein vollständiges Bild: Wann bricht der Durchsatz ein? Korreliert das mit Retransmissions? Wie lange dauert der Recovery?
Für den Wireshark-Filter, um TCP-Retransmissions zu isolieren:
tcp.analysis.retransmission or tcp.analysis.fast_retransmission
Und um doppelte ACKs zu sehen, die auf Paketverlust hinweisen:tcp.analysis.duplicate_ack
Mehr zur Interpretation dieser Signale findest du in den Artikeln TCP Retransmissions: Der stille Performance-Killer und Wie lese ich einen TCP Stream richtig?.Den aktiven Algorithmus ermitteln
Auf Linux kannst du den aktiven Congestion-Control-Algorithmus direkt abfragen:sysctl net.ipv4.tcp_congestion_control
Und ändern – zum Beispiel auf BBR:sysctl -w net.ipv4.tcp_congestion_control=bbr
Ob BBR verfügbar ist, prüfst du mit:sysctl net.ipv4.tcp_available_congestion_control
Auf einzelnen TCP-Verbindungen ist der Algorithmus aus dem Wireshark-Trace allein nicht direkt ablesbar – aber das Verhaltensmuster gibt dir starke Hinweise. Ein stabiler, nicht-sägezahnartiger Durchsatz spricht für BBR. Klassisches AIMD-Verhalten mit regelmäßigen Einbrüchen deutet auf CUBIC oder Reno hin.Das Bandwidth-Delay-Product als Referenz
Um einzuordnen, ob ein beobachteter Durchsatz theoretisch erreichbar ist, hilft folgende Formel:BDP = Bandbreite (bit/s) × RTT (s)
Ein Beispiel: 1 Gbit/s Bandbreite, 80 ms RTT → BDP = 80 Mbit = 10 MB. Das CWND muss also mindestens 10 MB groß sein, um die Leitung vollständig auszulasten. Wenn dein Trace zeigt, dass das Fenster regelmäßig weit darunter bleibt – hast du ein Congestion-Control-Problem, kein Hardware-Problem.Fazit – welcher Algorithmus ist der „beste”?
Die ehrliche Antwort: Es gibt keinen universell besten Congestion-Control-Algorithmus. Der richtige Algorithmus hängt von deiner konkreten Umgebung ab.
- Reno ist für moderne Hochgeschwindigkeitsnetze nicht mehr zeitgemäß – außer in sehr spezifischen Legacy-Kontexten.
- CUBIC ist der pragmatische Standard für Linux-Umgebungen und macht in den meisten Unternehmensszenarien einen sehr guten Job.
- BBR ist interessant für WAN-Strecken, Cloud-Verbindungen und Umgebungen mit nicht-kongestivem Verlust – aber nicht ohne sorgfältige Prüfung der Fairness-Auswirkungen in gemischten Netzen.
Was ich aus der Praxis mitgebe: Schlechter Durchsatz auf einer Verbindung ist selten nur ein Netzwerkproblem. TCP-Stack, Congestion-Control-Algorithmus, Window Scaling, Receive Buffer Size – all das spielt zusammen. Bevor du Geld in mehr Bandbreite investierst, lohnt sich ein sauberer Paketmitschnitt und eine strukturierte Analyse.
Wenn du in deinem Unternehmen Performance-Probleme hast, die sich nicht auf Anhieb erklären lassen – oder wenn du nach einem Netzwerkumbau merkst, dass Durchsatzziele nicht erreicht werden – kann eine professionelle Analyse den entscheidenden Unterschied machen. Ein einziger Blick auf den richtigen TCP-Stream-Graph hat schon manchen teuren Hardware-Tausch verhindert.
Das Problem ist reproduzierbar – aber die Ursache bleibt im Dunkeln?
Dann braucht es einen zweiten Blick auf die Pakete. Wireshark kennt die Antwort – manchmal fehlt nur die Erfahrung, sie darin zu lesen.
Als spezialisierter Netzwerkanalyst helfe ich dir dabei:
- Ursachen präzise zu lokalisieren – statt auf Verdacht Hardware zu tauschen.
- Komplexe Packet-Traces auszuwerten und in klare Handlungsempfehlungen zu übersetzen.
- Die Schuldfrage objektiv zu klären – mit Beweisen auf Paketebene, die das Fingerpointing zwischen Netzwerk- und Applikationsteam beenden.
Oft führt ein gemeinsamer, fokussierter Blick auf die Mitschnitte schneller zum Ziel als tagelanges Rätselraten. Im ersten Gespräch schauen wir uns gemeinsam die Ausgangslage an – Symptome, bisheriges Troubleshooting und mögliche nächste Schritte – bevor wir entscheiden, wie wir weiter vorgehen.
Schreib mir eine kurze Nachricht mit deiner Herausforderung – ich melde mich für ein unverbindliches Erstgespräch.